

Todavía recuerdo un congreso de Inteligencia Artificial en el CosmoCaixa de Barcelona allá por 2016. El consenso general, incluso por los propios ponentes, era que sí, se estaban haciendo progresos (sobre todo en métodos de machine learning con fines de algoritmos y clasificación), pero que todavía quedaban unos años hasta que hubiese un auténtico avance significativo del tipo “podremos hablar con nuestros ordenadores”. No sé si será que el tiempo pasa volando o si verdaderamente ha venido de sorpresa; el caso es que, si hace un año me hubieran preguntado por las IA, hubiera respondido de la misma manera que en aquel entonces.
Y vaya añito este último. Llego un poco tarde a la fiesta para hablar de las IA, pero creo que hasta mejor ahora que ha bajado un poco la espuma. Mi idea con esta entrada es ayudarme a mí mismo a documentarme del tema, y con suerte a quien llegue aquí. Será de forma simple, con pocos tecnicismos, sacando a colación sólo lo estrictamente necesario para (i) ayudar a entender cómo funcionan y las diferencias entre unos y otros tipos de IA, (ii) entender hasta dónde llega su potencial en la actualidad, (iii) despojar el tema de misticismo, y sobre todo para (iv) llevar la atención a lo más importante: cómo está afectando a nuestra sociedad y qué debemos saber o podemos hacer frente a lo que se avecina.
El artículo es largo, relativamente amateur-ish, y no creo que sea de lo mejor que he escrito. Es bastante probable que le añada o cambie cosas (sobre todo de formato, y para aclarar y añadir referencias) en los próximos días. No me considero un experto y he simplificado en algunos puntos (sobre todos los más técnicos) para centrarme en otros que creo más importantes. Bienvenidas son las correcciones y matices que se crean oportunas con tal de mejorar la compresión.
Y sin más preámbulos…
Esto es todo lo que voy a decir de las IAs.
Índice
- Qué es (y qué no es) una IA
- Varios tipos: clasificación y generación
- Cómo se hace una IA: trainings, datasets, y GPUs
- Cómo se usan: prompts
- Problemas
- Concepción
- Diseño, Desarrollo y Mantenimiento
- Aplicación
- Frentes de impacto real en una mundo capitalista
- Soluciones?
- Legislación
- Mi opinión final
- Enlaces, lecturas recomendadas, y fuentes de interés
Qué es (y qué no es) una IA
Las Inteligencias Artificiales (IA) son sistemas computacionales (programas o conjuntos de programas) diseñados para desempeñar funciones que, tradicionalmente, han requerido de inteligencia humana. Por ejemplo, para clasificar cosas, escoger entre varias opciones, o generar contenido (texto, imágenes, sonidos…).
A los humanos se nos da bien porque tenemos pensamiento simbólico y abstracto: un acceso previo a mucha información que, si bien no siempre consultamos de manera directa, son parte del bagaje de conocimiento que tenemos al haber aprendido todo tipo de cosas durante toda nuestra vida. A diferencia de la programación y lógica tradicional, muchas veces tomamos decisiones y contamos/creamos algo así o asá, de una manera o de otra, en base a información latente en que no pensamos activamente. Esto, hasta hace relativamente poco, no era propio de una máquina que se pudiera programar, y por eso se veía como algo remoto en el futuro.
Insisto en mencionar que son programas. Por mucho que “compartan” esa capacidad cognitiva con las personas, las IA no tienen conciencia ni emociones propias y operan únicamente en base a reglas y algoritmos programados. Pueden “aprender” de datos y mejorar su rendimiento con la experiencia (ver más abajo), pero carecen de la comprensión profunda y la empatía que nos caracteriza a las personas y que modula nuestras acciones. Distinto es que a nuestras mentes les dé la impresión de que podamos estar teniendo una conversación lógica con ellas, pero esto ocurre porque estamos habituados a reconocer patrones, ya que la barrera entre una conversación con una IA y una conversación casual se desdibuja en ocasiones.

Las IA no son nada nuevo. Con avances en neurología y el advenimiento de los primeros ordenadores en las décadas anteriores, el mismo Alan Turing ya comentó en los 50 que cualquier proceso de computación (deducciones, procesado de la información, y toma de decisiones) se podía expresar digitalmente, y que por tanto sería plausible crear una estructura digital “pensante”. Ya en ese entonces comenzaron los primeros empujones con el trabajo de Turing y máquinas que “jugaban” al ajederez; tras décadas de muchos frentes probando diferentes maneras, muchos altos y bajos, y una mejora sustancial de la tecnología, llegamos al presente con todas estas compañías haciendo lo que antes pareciera impensable. ¿Qué ha cambiado para que ahora sí se pueda hacer esto con las IA? Para saberlo hay que entender un poco sus entresijos.
Varios tipos: clasificación y generación
Del mismo modo que usamos nuestra inteligencia natural de distintas formas para resolver distintos tipos de problemas, existen varios tipos de IA para distintos tipos de tareas. Y del mismo modo que dos personas no tienen por qué llegar a la misma solución de igual manera, dentro de cada IA existen diferentes algoritmos que intentan aportar distintas “formas de pensar”. Estoy resumiendo mucho y muy fuerte, y aparte no soy un experto, de modo que sobra decir que es todo más complicado en el fondo. Dos de las que más comúnmente encontramos a día de hoy son:
- La IA de clasificación o discriminadoras se utiliza para asignar etiquetas o categorías a datos, como por ejemplo identificar si una imagen contiene un gato, o una matrícula, o la cara de cierta persona. Este tipo de IA es la que le permite a tu teléfono agrupar fotos por caras de familiares y amigos, o la que permite hacer recomendaciones personalizadas de películas en los servicios de streaming más populares. La tecnología subyacente se basa en aprender diferencias entre los elementos con los que trabaja, en base a parámetros y propiedades latentes. Este tipo de IA puede ser problemática ya que permite tomar decisiones semiautomáticamente sin tener en cuenta otros factores humanos, o por ejemplo pueden ser usadas para potencialmente violar el derecho a privacidad de personas al ser capaces de general “perfiles” de preferencias de contenido que acaban sabiendo de ti más que tú mismo.
- Las IA de generación son capaces de producir contenido original, como textos (de cualquier tipo, incluyendo código), imágenes (a partir de descripciones, de otras imágenes, u otro tipo de datos) o audio (generadores de voz en base a texto, generadores de música, canciones…). Aquí se incluyen modelos de lenguaje (LLM) como ChatGPT, pero también generadores de gráfico tipo MidJourney, DALL-E, Stable Diffusion, y otras similares. Estas son las que más han dado que hablar recientemente, por su potencial creativo y al mismo tiempo su potencial de violar la propiedad intelectual y los derechos de uso, así como de estar en una área legal muy desdibujada de lo que se considera “plagio”.
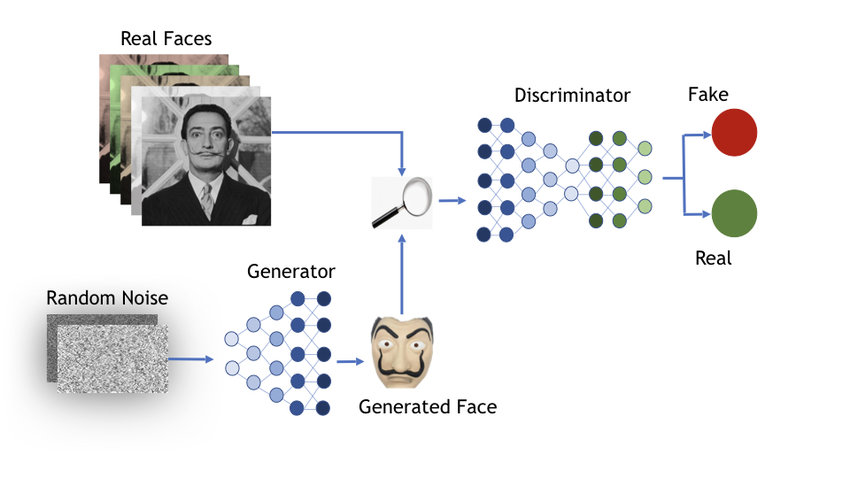
Cómo se hacen: training datasets, y GPUs
Para que las IA puedan desempeñar su función, hay que enseñarles o entrenarlas, de igual modo que se enseña a las personas a hacer algo nuevo. Y cómo? Pues en algo parecido a “ejercicios de práctica”. Imaginemos un ejemplo: queremos una IA que sepa detectar caras de personas o animales en fotos. Para este entrenamiento, se elige bien el tipo de material que se le va a enseñar (es decir, conjuntos enormes de datos ya sean imágenes, texto, sonido, o de todo; según dependa lo que se quiera conseguir), y se divide en dos:
- A una parte se le llama “conjunto de entrenamiento” o “training dataset”. Estos datos son tomados por el programa de la IA, que los usa para detectar patrones y relaciones relevantes para la tarea que realizarán. Por ejemplo, muchísimo texto (cientos y cientos de GB; como libros, obras públicas, contenido de publicado en páginas de internet…), o muchísimas imágenes (a veces con descripciones y texto asociado para ayudar a establecer las relaciones entre conceptos). En el caso de nuestro ejemplo, sería una base de datos gigante con fotos que tienen personas, animales, ambas o ninguna; respectivamente etiquetadas. La idea es poner a correr el programa de la IA para ver si acierta en su decisión. A base de acierto y error, se recompensa a la IA cuando toma la decisión correcta y se penaliza cuando no. Esto le permite autoajustarse y optimizarse poco a poco (es lo que llamamos “machine learning”).
- La otra parte de los datos se consideran “conjunto de evaluación” o “evaluating dataset”. Tras muchísimas iteraciones o rondas de aprendizaje, se evalúa si el programa es capaz de desempeñar bien su función (por ejemplo, detectando animales o caras de personas en fotografías, o escribiendo texto fluido y coherente).

Lo que ocurre en medio de los dos pasos no siempre es sabido. Depende del diseño de la IA, esto puede ser como una caja negra. Algo parecido a cuando no encuentras las palabras para explicar cómo piensas, cómo se te ocurre algo, o cómo te sientes: son procesos intrínsecamente aprendidos y muchas veces emergentes. Las IA aprenden propiedades latentes sin llegar a comprender el significado abstracto de las cosas con las que trabajan.
Una vez entrenada, o “enseñada”, la parte sustanciosa de la IA está lista para funcionar. Añadida a esta parte sustanciosa hay, normalmente, otras capas de software que ayudan al usuario a comunicarse con la IA. Esto puede ser, por ejemplo, una interfaz de línea de comandos, un programa externo que llama a la IA, una herramienta gráfica con opciones, una web, etcétera. Con estas partes es con lo que solemos interaccionar como usuarios, proporcionándoles “prompts” o “datos de entrada”.
Cómo o dónde se entrenan
Teniendo esto, ¿podemos entrenar y tener una IA propia que nos ayude en nuestras cosas de manera personalizada? Para nosotros meros mortales no es tan sencillo. Lejos de ser elegante, el entrenamiento es una cuestión de fuerza bruta (como muchas otras cosas a día de hoy en la computación moderna). Y nuestro hardware actual convencional (los componentes y piezas de nuestras máquinas), el que tenemos en casa o incluso en ordenadores domésticos potentes, no es suficiente.
Poner a entrenar a una IA requiere de muchísima capacidad de computación para la que incluso los CPU (procesadores, cerebros de los ordenadores) convencionales se quedan cortos. Esto sucede porque los cerebros de nuestros ordenadores trabajan en serie, de manera secuencial. Para nuestras tareas diarias, calcular en serie no supone mucho problema (eso de que tengamos ordenadores “multitarea” es un truco muy apañao que no requiere procesos en paralelo). Pero para un entrenamiento de IA se requieren hacer muchísimos cálculos, pero muchísimos, por lo que hacerlos secuencialmente tardaría demasiado. Esto fue limitante hasta que se pensó en usar otro tipo de hardware que, por razones completamente ajenas, se basa en hacer cálculos en paralelo: las tarjetas gráficas o GPUs (sí, las de videojuegos y renderizado de películas o efectos).
Para este tipo de gráficos, especialmente los de videojuegos muy realistas, se necesita plasmar en pantalla, con muchísima exactitud y puntualidad, la posición y características de miles de triángulos que forman los objetos, personas, o cosas moviéndose e interactuando entre ellas, más su traducción a píxeles para que nuestros ojos lo vean. Y no sólo una vez. Sesenta, incluso ochenta, por segundo, para recrear movimiento. Para esta tarea monumental las GPU (los cerebros de las gráficas) cuentan con capacidad de cálculo en paralelo, así que las gráficas vienen que ni pintadas para las IA (y para cualquier tarea que requiera de fuerza bruta computacional colosal, como modelado matemático, la criptografía, o la tecnología de blockchain para las criptomonedas). Por eso, también, son tan demandadas y caras a día de hoy.

En resumen: para entrenar IAs con datos masivos hace falta un dispositivo con alta capacidad de procesamiento, especialmente en paralelo con el uso de GPUs, así como almacenamiento para los datasets. No es de extrañar que muchas de éstas se desarrollen en grandes compañías o centros con muchos recursos. Actualmente hay iniciativas modernas para resolver este problema, como diseccionar la parte algorítmica de la IA en sub-bloques pre-entrenados que pueden ser reutilizados para fabricar nuevas IAs o nuevos programas que usen IAs.
Cómo se usan: prompts
A día de hoy, las IA están presentes en todas partes con todo tipo de aplicaciones y medios. Las más conocidas (ChatGPT, MidJourney, Stable Diffusion) funcionan todas en base a prompts, o “instrucciones” (a falta de una mejor palabra), que proporcionan una guía de lo que se quiere conseguir. Dado que a las personas se nos da bien hablar y comunicarnos en un lenguaje natural, que podemos matizar de forma dinámica a lo largo de un texto, esta tecnología ha predominado.
Qué ocurre? Pues dos cosas; primero, que como humanos somos imperfectos y el lenguaje siempre tiene una parte de “falta de comunicación”. Segundo, que las máquinas siguen siendo máquinas, y por mucho que hayan sido entrenadas para trabajar con lenguaje natural, van a seguir haciendo cosas extrañas si no te entienden bien (y más aún si sus procesos son latentes). De modo que se ha formado toda una para-cultura alrededor de la “construcción de prompts”, según el tipo de la IA, e incluso de la versión, con cambios muy drásticos en “cómo le gusta a la IA” sus instrucciones incluso en el lapso de pocos meses.
Pero es que es realmente útil dar con la clave de lo que mejor entiende una IA. No es lo mismo decirle a una IA: “hazme un programa que convierta de un formato X a un formato Y” que decirle “necesito un script de python que haga los pasos 1,2,3,etc en los datos A,B,C,D del archivo en formato X, leyendo línea a línea, lo guarde en tal o cual estructura, y lo vuelque a un archivo en formato Y”. El resultado de la segunda petición será más claro y preciso. Y de la misma manera, no es lo mismo decirle “hazme una imagen de un pokémon Godzilla” que “hazme una imagen de Godzilla en el estilo de acuarela de finales de los 90s de Ken Sugimori para la revista Game Freak”. Y de la misma manera, no es lo mismo decirle “pásame un enlace de streaming pirata” que “qué webs de streaming pirata me recominedas evitar si quisiera consumir contenido de manera legal”. Así que a la vista está que depende enteramente de quién las use y con qué motivo detrás.
Problemas
He tocado en un par de cosas, pero creo que estará bien exponer los problemas en el mismo orden en el que hemos ido explicando: desde la concepción, a los datasets, a los resultados, al uso, y a las consecuencias.
1. Concepción

#/media/File:Terminator(Future_War).png){kind=link}
El primero de todos radica en la concepción de IA: la gente tendemos a confundirlas con entidades capaces de tomar decisiones por sí mismas y actuar con agencia propia, que de por sí son malvadas y capaces de reemplazarnos. Esto a día de hoy no es así. Las IA son herramientas, programas o conjuntos de programas o partes de otros programas, que requieren de personas que las entrenen, las desarrollen y las mantengan. Pero, como siempre, el mercado de periodismo compite por nuestra atención y una abundancia de medios de mala calidad, que responden a intereses y ganancias, generan contenido muy amarillista (que roza el tono DoomsDay) que no informa bien. Y esto cala en la opinión pública, por simple exposición. Es lo mismo que pasa con tantos otros temas delicados: necesitamos de mejores medios que velen por hacer buena comunicación, y divulgación de lo que significan y suponen estas herramientas. Las IA no son malvadas, de la misma manera que un modelo estadístico no es malvado. Lo será (o no) el uso que se les dé y que se les permita dar. No hace falta elevarlas a dioses máquinas para otorgarles la capacidad de causar estragos: ya hay decisiones que se toman automáticamente sin personas de por medio, que deciden las vidas de los demás. Volveré a esto y a lo de “reemplazarnos” un poco más abajo.
2. Diseño, desarrollo y entrenamiento

Hay docenas de ejemplos documentados en la prensa de cómo el racismo y la discriminación son sesgos reales en el desarrollo de herramientas de IA. La composición de los datos de entrenamiento determina lo que sale de las IA, de modo que un dataset poco diverso dará lugar a resultados poco diversos. Lo mismo sucede con imágenes de contenido o alta carga sexual, que pueden ser no deseables según qué herramienta de IA. Para prevenir esto, los datasets deben de ser curados manualmente por personas. Ya existen bases de datos curadas y públicas para este objetivo, pero muchas empresas privadas que desarrollan sus propias IA usan datasets propios no compartidos, y la curación la hacen por subcontrata a terceros, normalmente empresas en países en desarrollo con pésimos sueldos y condiciones laborales. Un poco lo que pasa con las fábricas de Inditex.
Y tampoco nos quedamos cortos de controversias en el desarrollo y mantenimiento. Muchas de las IA se ejecutan y despliegan en servidores a gran escala, que requieren de una infraestructura de virtualización y contenedores que es propensa a irreproducibilidad, por no hablar del coste de tiempo y económico que puede suponer el testeo y despliegue. La realidad es que, aunque mucho se construya sobre tecnología de código abierto, el desarrollo, configuración, puesta a punto y ejecución de las IA no está en manos de todos por el tremendo coste (en horas de cálculo en la nube, precio de las GPUs, e incluso facturas de luz). Con la subsecuente frustración de los desarrolladores, tanto empleados como por cuenta propia.
Asimismo, la alta competitividad y demanda del sector requiere de implementaciones anidadas (un ejemplo exagerado: servidores con máquinas virtuales que montan contenedores que ejecutan pipelines con entornos virtuales que usan bloques de código-software en distintos lenguajes con librerías de todo tipo), exacerbando todavía más la “inflamación” y la pobre higiene digital, tanto en tamaño del software como en la pobre calidad del código y de los outputs, que viene acuciando en estos últimos años (esto en sí es un tema del que veo muy poca conversación y del que me gustaría escribir alguna vez).
3. Aplicación
Las IA llevan varios meses fuera y su impacto ya es real. Internet se ha plagado de contenido generado por IAs, y no tiene pinta de que vaya a parar pronto. Con este problema, la web de SEO por y para scrapers orientada a marketing se vuelve aún más difícil de navegar por ser más difícil de distinguir y destilar contenido de valor. Por no decir que ese contenido autogenerado está siendo retroalimentado a y consultado por otras IAs, como el famoso caso de Bing y Bard autosugestionadas, generando vórtices de desinformación de los cuales se predice que ya no hay escapatoria — solo podemos mitigar su impacto en nuestras vidas.

La falta de limitaciones ha hecho que, como parte de este contenido autogenerado, campen a sus anchas imágenes que hacen uso ilegítimo de la propiedad intelectual, sin estar aún muy claro si se puede considerar como plagio. Muchos artistas que jamás dieron consentimiento alguno de que su arte podía ser usado de tal manera se han ido sumando a la causa de prohibir el derecho a usar sus imágenes para entrenar a IAs y haciendo que las empresas eliminen su contenido de los datasets, solo para que dicho contenido vuelva a ser reintroducido por terceros. Los problemas de mala aplicación se extienden al audio y vídeo. Si hace unos años el deepfake ya puso en la mesa el tema de la suplantación de identidad, ahora es más peligroso porque las IA generativas de voz son muy buenas en imitar las voces auténticas, agravando aún más el problema de la desinformación. Es muy gracioso escuchar las voces de Obama, Biden y Trump en un server de Discord quejándose de anime, hasta que te das cuenta de que podrían hacer lo mismo con la voz de cualquiera para cometer estafas, o para manipular a las masas en las redes sociales (algo que ya tuvo precedentes con las elecciones de Trump, el auge de la extrema derecha, y otros discursos de odio en Asia).
Pero no puedo acabar esta sección sin mencionar el uso incorrecto que le da la gente. Desde estudiantes abusando al máximo de ChatGPT (lo cual creo que dice más de cómo está planteado sistema educativo que de los estudiantes), a abogados sancionados por consultar a chatGPT por casos jurídicos en la literatura sin cruzar referencias a mano, o a profesores que suspenden masivamente a estudiantes por haberle ido preguntando a chatGPT si había escrito los papers de cada alumno, uno por uno (y recibir confirmación de un programa offline diseñado para generar lenguaje natural y no como una herramienta de consulta online; menos aún de contenido generado por otras personas en la propia aplicación). De nuevo insisto en que por eso es crucial una buena divulgación por parte de los medios.
4. Frentes de impacto real en un mundo capitalista
Todo lo que he mencionado en la sección anterior pinta una escena para nada positiva. A menos que hayas estado desconectado del mundo los últimos meses, ya sabrás la reacción e impacto en el mundo real tampoco mejora.
No sé por dónde empezar aquí. Pero todo se relaciona con los movimientos de las empresas y del mercado a raíz de la llegada de las IA. Hay innumerables noticias de recortes en sueldos o directamente gente despedida meses después de haber salido chatGPT, desde equipos de ética en Google y OpenAI, hasta empleados rasos (como escritores de blog, y otros tipos de creadores de contenido) cuyo trabajo puede ser reemplazado por chatGPT, no en calidad pero sí en cantidad (y todos sabemos que esto se mueve por cantidad). Y por coste 0 frente a tener a personas en nómina. Como siempre, reduciendo costes y aumentando beneficios. También han sido muchos los testimonios de diseñadores gráficos o ilustradores autónomos que pierden media agenda de contactos y clientela habitual, de esas que te haces en toda una vida.
Las propias empresas como OpenAI no son del todo claras en sus métodos. Hay muy poca transprencia por su parte, tanto como qué hacen con los datos de los usuarios (a los problemas de privacidad ya existentes en el mundo se suman ahora el uso dudoso que las empresas vayan a dar a los contenidos generados por los propios usuarios, así como a los prompts) como en la reproducibilidad y archivo digital de sus productos: las llegadas de nuevas versiones van acompañadas de la eliminación de las previas, sin soporte alguno, sembrando dudas y cuestiones de su funcionamiento y del papel que deberían tener en preservar y documentar una tecnología con tanto potencial tanto para lo bueno como lo malo. Y es que la ciberseguridad en esta tecnologia es inexistente porque acaba de nacer. Tenemos el ejemplo anterior de suplantar voces, generar contenido desinformante con el objetivo de sembrar confusión y manipular, y también tenemos ejemplos más inesperados de ataques a partir de inyecciones en los prompts. Mi conocimiento es escaso así que me remito a un post que lo explica muy bien.
Y permítaseme el esperpento, pero la guinda del pastel es la reacción de las personas con mayor tracción en los medios: todo esto sucede enmedio de un mar de techbros neoliberales zumbando en las redes sociales con sus perfiles intachables y emojis en la biografía, posteando cada 15 minutos hilos protips y newsletters, saltando cada 3 meses entre puestos de trabajo con títulos tan absurdos como “prompt curator”, en startups un poquito dudosas, fardando de recursos y con un retinte muy clasista de “la culpa de que tu vida no sea como la mía es tuya y sólo tuya”. Esta gente me recuerda a los criptobros, porque sorpresa, son los mismos. El tema IA tiene demasiados paralelismos el tema blockchain y las criptomonedas. Ambos campos experimentaron un crecimiento vertiginoso, casi simultáneo (con uno-dos años de diferencia) y han capturado la atención global. Y como en el otro caso, han surgido infinidad de polémicas y debates en torno a su impacto en la sociedad. Lo último que quería comentar es, quizá, lo que más nos debería importar de verdad, y que es compartido con el boom cripto de este capitalismo tardío: la huella medioambiental. La cantida de energía que se destina, directa o indirectamente, a fabricar GPUs y a alimentar los centros de computación, no hace más que sumarse al problema cripto que ya existía anteriormente. En lugar de hacer frente al problema real, la gente con recursos materiales para dirigir las cosas a puerto prefieren mirar a otro lado y seguir sacando su parte del pastel, de un pastel que se nos va a la mierda con la crisis climática.
Soluciones?
Haciendo broma con lo de proveer un buen prompt, no sé si la pregunta correcta sería “¿Cuál es la solución a estos problemas?” porque eso daría pie a proponer el NO usar las IAs. Quizá sería algo más como “¿Qué podemos hacer para combatir esos problemas?” y para mí la respuesta es clara, y por una vez no voy a repetir lo que veo viendo en otros medios de “qué podemos hacer a nivel individual”.
La respuesta es, simple y llanamente, Legislación. Es absurdo pensar que usar una herramienta como ésta sin límites debiera estar exenta de delito, por mucho que le duela a los techbros del párrafo de arriba. Se supone que para éso tenemos los gobiernos y otras herramientas democráticas. La conversación de las IA debe de girar y enfocarse a “qué podemos permitir y no permitir”. Salvo algunas cosas en Bruselas, y más relacionadas con privacidad y derechos de propiedad intelectual, ahora mismo no hay debate sólido al respecto. No en los medios, ni en la política (si acaso, un titular diciendo que el gobierno iba a “promover su uso”, whatever that means). Estas herramientas han llegado para quedarse, así que quizá debería de empezarse a pensar en medidas como las siguientes:
- Generar definiciones legales y crear un marco de referencia tanto a nivel de conceptos y terminología (joder, si la cerveza y otros productos básicos están definidos por ley…), distinguiendo por ejemplo ideas como “usuario inmediato” (tú y yo), “autor de los datos” (las personas que han generado el material que entra a las IA), maneras de medir la transparencia y el consumo energético …
- Proteger la privacidad y los derechos de los usuarios inmediatos.
- Proteger la privacidad y los derechos de las personas generadoras de los datos de entrenamiento.
- Proteger la privacidad y los derechos de los autores del contenido de los datos de entrenamiento.
- Fomentar la divulgación y la buena praxis en los medios de comunicación (en general y en relación a este tema)
- Fomentar la formación de trabajadores en el uso y entendimiento de herramientas de IA
- Fomentar la investigación y el desarrollo de herramientas de mitigación de desinformación generada por las IA
- Actualizar la legislación vigente que pertenga a los derechos de uso, propiedad intelectual, plagiarismo, etcétera.
- Definir estándares de ética, transparencia y políticas de acceso abierto, y exigirlos a las empresas de IA que deseen comercializar su producto, con especial hincapié en empresas grandes (tecnológicas o no tecnológicas).
- Definir estándares de calidad de datos de entrenamiento (p.ej. diversidad, sesgos, etcétera), y exigirlos a las empresas que deseen comercializar su producto.
- Limitar el consumo energético vinculado a las IA, con especial hincapié en empresas grandes (tecnológicas o no tecnológicas).
- Restringir la capacidad de empresas privadas a proceder con despidos relacionados con percepción de beneficios en relación al uso de IAs
- Auditar las empresas en relación a los beneficios por uso de IAs.
- Auditar periódicamente a las empresas dedicadas a la comercialización con IAs para evaluar su impacto.
Yo que sé, la lista es larguísima y esto sólo son ideas que se me ocurren ahora. Pero creo que se entiende por dónde van los tiros. Imagina si esta conversación fuese más abierta a día de hoy. No puedo ser yo el que tenga la solución única ni las medidas únicas (Dios me libre), pero creo que como individuo es lo que me toca hacer.
Mi opinión final
Por lo disruptor de esta tecnología, es vital que ésta entre a la sociedad de manera supeditada y asistida por los mecanismos que están al servicio de los ciudadanos y los usuarios. Por eso creo que es fundamental la concienciación del alcance que tienen, de los problemas que presentan. Y con ello también promover y exigir medidas adecuadas que nos protejan, tanto a los usuarios como a los artistas como al medio ambiente.
La mezcla de la situación global tan desesperanzadora y nuesto decrecimiento en capacidad de atención hacen que colectivamente reaccionemos a nuevos saltos tecnológicos como agua de Mayo, pero la realidad es que todo lleva tiempo. Son herramientas muy nuevas y están en una etapa crucial para determinar de qué manera acabarán transformando el mundo. Y tal y como están las cosas, cualquier medida que busque reorientar las cosas sólo pueden venir por vías colectivas como la legislación.
¿Podríamos por una vez hacer las cosas en condiciones?
Enlaces, lecturas recomendadas, y fuentes de interés
(iré ordenando, expandiendo, y referenciando internamente esta lista de enlaces en los próximos días)
- https://towardsdatascience.com/stable-diffusion-best-open-source-version-of-dall-e-2-ebcdf1cb64bc
- https://simonwillison.net/2023/Apr/14/worst-that-can-happen/
- https://medium.com/freely-sharing-the-sum-of-all-knowledge/wikipedias-value-in-the-age-of-generative-ai-b19fec06bbee
- https://www.theverge.com/2023/7/21/23802274/artificial-intelligence-meta-google-openai-white-house-security-safety
- https://www.nature.com/articles/s41580-021-00407-0
- https://www.enriquedans.com/2023/07/lo-que-hoy-utilizamos-no-son-redes-sociales.html
- https://vickiboykis.com/2023/07/18/what-we-dont-talk-about-when-we-talk-about-building-ai-apps/
- https://www.washingtonpost.com/technology/2023/03/30/tech-companies-cut-ai-ethics/
- https://www.theverge.com/2020/5/30/21275524/microsoft-news-msn-layoffs-artificial-intelligence-ai-replacements
- https://theconversation.com/big-tech-is-firing-employees-by-the-thousands-why-and-how-worried-should-we-be-198418
- https://www.bloomberg.com/news/newsletters/2022-05-13/tech-companies-coddled-their-employees-now-they-re-firing-them
- https://www.wired.com/story/fast-forward-workers-are-worried-about-their-bosses-embracing-ai/
- https://futurism.com/the-byte/microsoft-10000-layoffs-openai
- https://www.indiatoday.in/technology/features/story/why-are-tech-companies-firing-thousands-of-engineers-it-is-not-about-saving-money-honey-2375516-2023-05-06
- linuxadictos.com/el-fin-de-la-burbuja-de-la-inteligencia-artificial.html
- https://www.forbes.com/sites/paultassi/2023/06/21/artists-are-mad-about-marvels-secret-invasion-ai-generated-opening-credits/
- https://front-end.social/@fox/110846484782705013